Abalone Modeling Performance:
Are Physical Characteristics Better Predictors of Age or Sex?
ROLE:
Data Engineer
TIMELINE:
September- October 2024
TEAM:
2 Data Engineers
1 Data Analyst

SKILLS:
Clustering
Classification
Machine Learning
-
This project evaluates the performance of models trained on UC Irvine’s Abalone dataset to model the age and sex of new abalone specimens. We compare key metrics for both clustering and classification models; to see if both agree on which attribute is most closely linked to the data features.
-
The data was sourced UC Irvine’s Machine Learning Repository, and was created in 1994 by the Marine Resources division of Primary Industry & Fisheries in Tasmania, before being donated to the university in 1995.
Total abalone samples: 4176
1307 males
1342 females
1527 infants (unknown sex)
Data features (input):
Length (mm)
Diameter (mm)
Height (mm)
Whole weight (grams)
Shucked weight (grams)
Viscera (grams)
Shell (grams)
Rings (integer count)
Output features:
Sex (classification)
Cluster assignment (clustering)
-
1.Data pre-processing
A. Data was split into 4 separate dataframes:
age_data
sex_data
age_labels
sex_labels
B. In age_labels, records labeled as male or female are relabeled as “adult”.
This data preprocessing will allow us to evaluate the models performance on the test data and to compare models trained on sex and age.
C. Both age_data & sex_data are scaled using sci-kit learn’s StandardScaler to prevent feature dominance.
D. A 2D projection of age_data is created so that cluster assignments can be visualized through scatter diagrams later
2.Metric Evaluation
A. Models trained using age & sex labels are evaluated using standard classification metrics
B. Clustering performance is measured via silhouette scores and how well clusters reflect the actual distribution of age and sex labels.
-
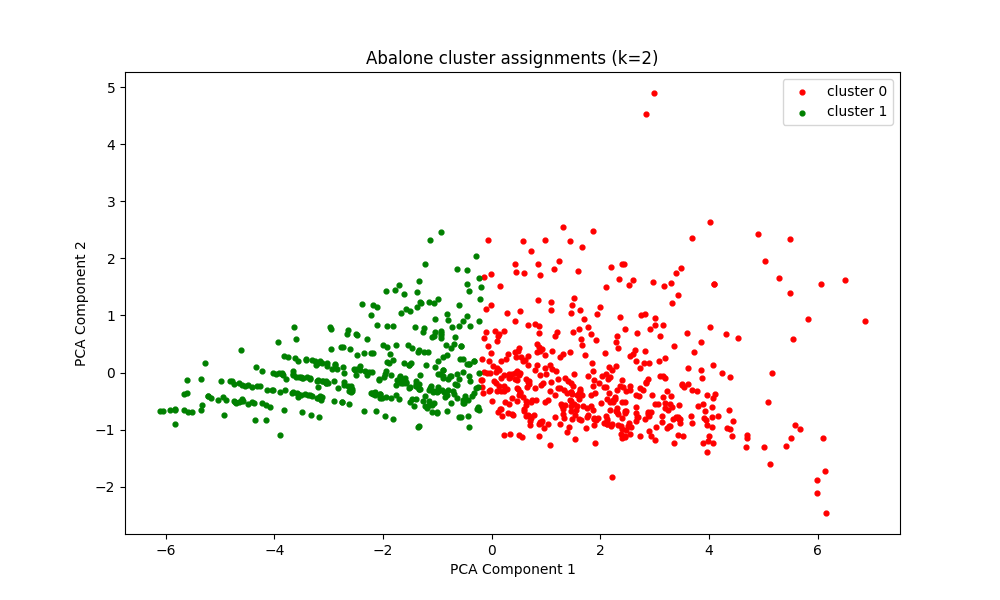
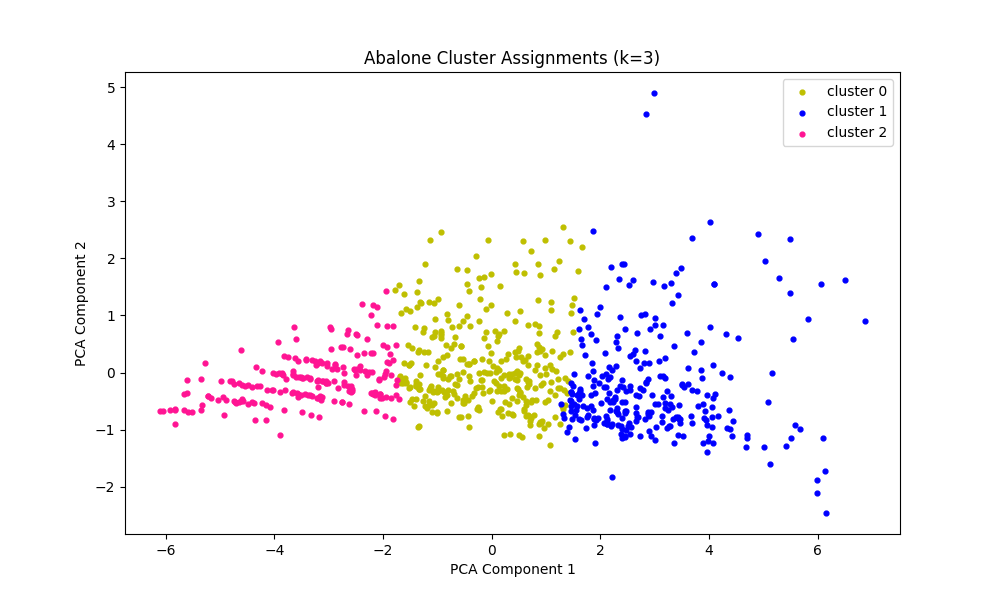
K-Means Clustering
Silhouette Scores
2 Clusters = 0.4695
3 Clusters = 0.3848
Multi-Layer Perceptron Classifier
Age Data
Accuracy = 80.14%
Precision Score: 78.12%
Recall Score: 78.79%
F1 Score: 78.42%
Sex Data:
Accuracy = 52.99%
Precision Score: 52.32%
Recall Score: 52.86%
F1 Score: 52.27%
-
The data seems to be best separated into 2 groups, with age (adult vs. infant) being most accurately modeled using the input features, as opposed to sex (male, female, infant). This is supported by the high accuracy value of the age-based classifier ~80%, the fair silhouette score from the 2-Means clustering analysis, and broad alignment of the cluster point cloud with the actual distribution of the projected data. The physical characteristics of an abalone specimen appear to be a good predictor of whether they are an adult or infant. More fine grain prediction of age may be possible using regression techniques.
-
Lack of cross-validation
classification metrics are highly subject to sampling bias
Average silhouette scores lack nuance
Silhouette plots could show the degree of definition for each cluster
Age modeling can only separate adults from infants
More precise age prediction may be possible via binning or use of regression techniques on ring count
Graphical Analysis
Cluster Assignment Scatter Plots
(20% of all data points were randomly selected for plotting to reduce graph clutter. Broad visual trends are the same as in the full dataset.)
The multi-layer perceptron does an good job of correctly predicting the age group of new specimens. After running multiple tests with other random seeds, it seems slightly more likely to misclassify an adult specimen as an infant.
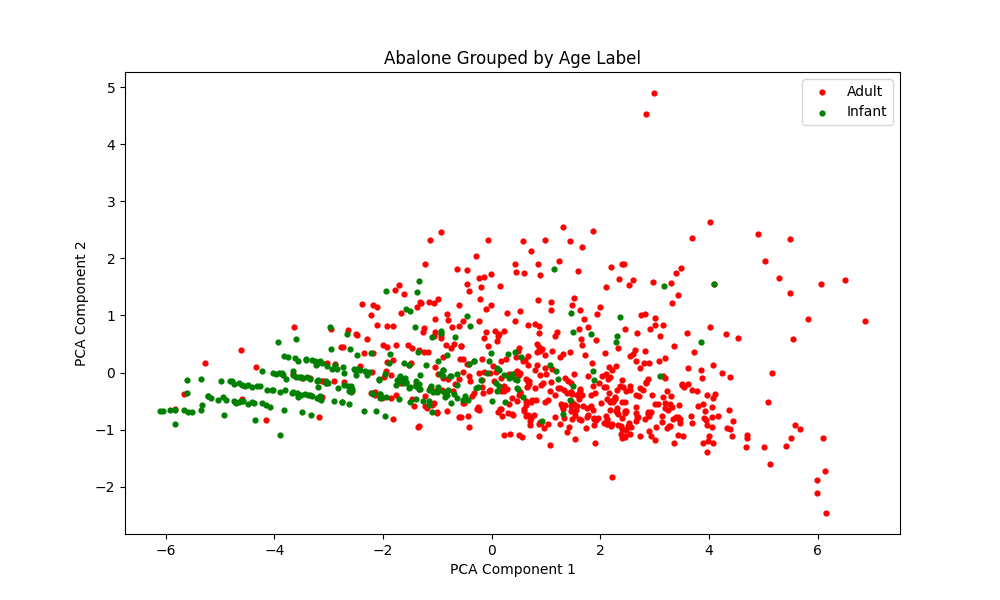
The cluster assignments for the 2-Means clustering model align fairly closely with the actual distribution of adult and infant specimens. Considering the substantial overlapping section between the 2 classes, and oblong shape of the actual label groups, this is impressive performance from a K-means model.
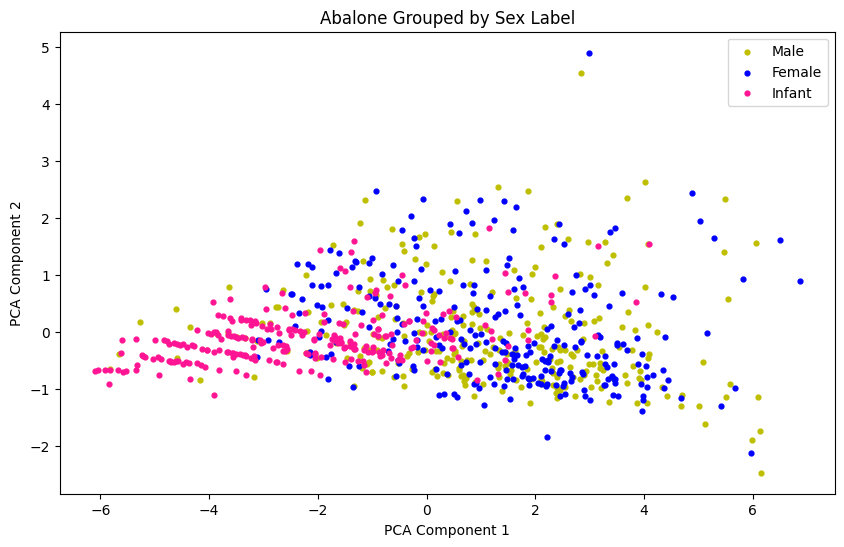
The cluster assignments for the 3-Means clustering model aligns somewhat poorly with the actual distribution of sex labels in the data. This is likely because of the low level of separation of the male and female samples, and the poor cohesion of the male sample group.
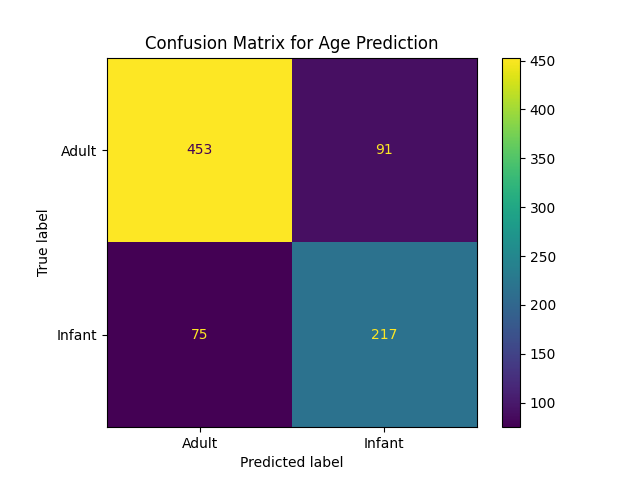
2. Confusion Matrices
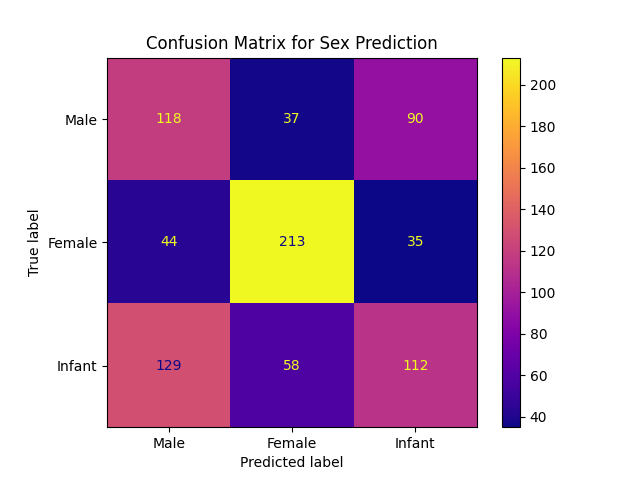
Interestingly, despite the projected data points having poor separation between the male and female specimens, the perceptron classifier seems to confuse male and infant specimens most often, while being the best at correctly predicting the sex of female abalone. Overall though, the sex classification performance of this model is poor.